
The Ultimate Guide to Conversion Rate Optimization for Any Business
Whether you’re a seasoned marketer or just starting out, conversion rate optimization (CRO) is a powerful tool that can boost your sales, leads, and overall

As a digital marketer or ecommerce website owner, how your site ranks on search engine results pages could make or break your business.
There are many things you can do to control the way your website is ranked, both on and off your home page. Things like SEO and keyword research might come to mind but are you familiar with your robots.txt file?
It plays a big role in how your site is indexed and ranked so you’ll want to pay close attention to it.
Let’s talk about what a robots.txt file is, how it affects your SEO, and how and when you should use it on your site.
A robots.txt, also known as Robots Exclusion file, is a text file that tells search engine robots how to crawl and index your website. It is a key technical SEO tool used to prevent search engine robots from crawling restricted areas of your site.
How these robots crawl your website is very important in terms of how your site is indexed. In turn, this has huge implications on how your website ranks on search engine results pages.
Sometimes, you will have information or files on your site that are important to the function of your site but aren’t necessarily important enough to be indexed or viewed. When you install a robots.txt file, it will block those files from being crawled.
A robots.txt file exists on the root of the domain. It will look like this:
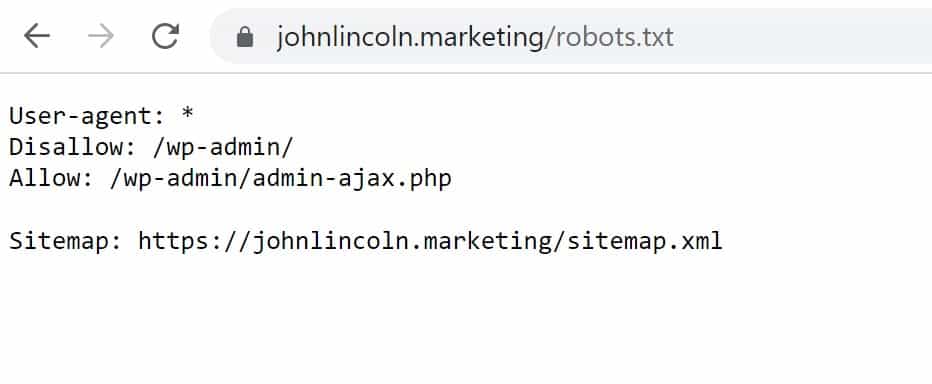
Keep in mind, this file only applies to this specific domain. Each individual subdomain or subpage should have its own robots.txt file.
Google explains all of the specifications necessary in their guide but, in general, it should be a plain text file encoded in UTF-8. The records should be separated by CR, CR/LF, or LF. While each search engine has its own maximum file size limits, the maximum file size for Google is 500KB.
The goal of your site should be to make it as easy to crawl as possible. Since this file will interrupt the crawling and indexing a bit, be picky when it comes to deciding which page of your site requires a robots.txt file.
Rather than always using a robots.txt file, focus more on keeping your site clean and easily indexable.
However, situations requiring a robots.txt file are not always avoidable. This feature was made available to improve times of server issues or crawl efficiency issues.
Examples of these issues include:
If you have an instance on your site where a Googlebot could get trapped and waste time, you should install a robots.txt file. Not only will this same indexing time but it will also improve the way your site is indexed and later ranked.
While a robots.txt file should be used sparingly, there are situations when they should definitely not even be considered.
Examples of these situations are:
A robots.txt file is very helpful when it comes to crawling but, if used incorrectly, it does have the ability to do more harm than good.
There is a standardized syntax and specific formatting rules to follow when it comes to preparing a robots.txt file.
The three main robots.txt files are:
There are also some rules to follow when creating your robots.txt file. Let’s explore them.
Within the file, you can add comments. These lines start with a # and are ignored by search engines. They exist solely so that you can add in notes or comments about what each line of your file does and when and why it was added.
You can also specify a block of rules to a specific user agent. To do so, use the “User-agent” directive. This will instruct certain applications to follow these rules while allowing others to ignore your instructions.
The most comment specific user agent tokens are:
While these are a few of the most popular specific user agent tokens, this list is far from complete. Be sure to check for more on each search engine’s website: Google, Twitter, Facebook, Bing, Yandex, and Baidu.
You can also insert a sitemap directive into your robots.txt file. This will tell search engines where to find the sitemap.
A sitemap will expose all of the URLs on a website and further guide search engines on where your content is located.
While this addition helps search engines discover all of your URLs, your sitemap will not appear in Bing Webmaster Tools or Google Search console if not manually added.
If you want a certain URL string to be blocked from search engine crawling, using a pattern matching URL in your robots.txt file is much more effective than including a list of complete URLs.
To use this tool, you’ll need the $ and * symbols.
The * symbol is a wildcard that can be used to represent any amount of any character. It can be used as many times as you would like in any area of the URL string.
The $ symbol signifies the end of a URL string.
For example:
Pattern matching URLs is a very effective way to block a large number of URLs or related URLs.
To block particular content from being viewed, you’ll want to use the Robots.txt disallow rule.
When you insert Disallow: before your symbols, search engines will know to ignore whatever URLs are produced by those symbols.
For example, the code below will block Google’s bots from crawling any of your URLs that start with a lowercase a:
User-agent: googlebot
Disallow: /a
On the flip side, if you want to specifically point out a URL to be crawled, adding “Allow:” will override a Robots.txt disallow rule and ensure that it is viewed.
This can be used in situations where you want one or two pages of a large group of content viewed, while blocking the remainder of that group.
Robots.txt noindex is a tool that allows you to manage search engine indexing without using up a crawl budget. It ensures that a particular URL is not indexed.
However, Google does not officially recognize noindex so while it works today, it’s important to have a backup plan in case it stops working tomorrow.
Like any powerful web tool, robots.txt has its issues. Some of them include:
All of these issues are small when handled properly but can compound to larger issues when neglected. To minimize any negative impact, be sure to keep your robots.txt file up to date and accurate.
The SEO best practice that you can follow is to be sure to save and test your robots.txt file accurately.
You can complete this task in your Google Search Console account. Using the tester tool, you can see which parts of your site are being crawled and which aren’t.
If you find that some of your content isn’t being crawled properly, you’ll know that you need to update your robots.txt file.
In addition, an improperly-installed robots.txt file can cause Google to ignore your site altogether. When your site is not crawled and indexed, it won’t appear on any search engine results pages.
Robots.txt can be a really cool tool that can benefit your site in a positive way. However, it can do a lot of damage if not used properly.
Be sure that you’re installing your file correctly and updating it regularly to see the best results from this process.
Still confused? You can always find a quality website developer to walk you through the process!


Whether you’re a seasoned marketer or just starting out, conversion rate optimization (CRO) is a powerful tool that can boost your sales, leads, and overall

Feeling overwhelmed by the sea of SEO companies out there? You’re not alone! Choosing the right partner is crucial for achieving your online marketing

In 2024, business blogging is not only still relevant – it’s a critical component of any content marketing strategy. Companies that blog generate 67% more
